TouchAnything
The First Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video
1Harbin Institute of Technology, Shenzhen
2Meituan Academy of Robotics
3Tsinghua Shenzhen International Graduate School, Tsinghua University
✉Corresponding author: shuoyang@hit.edu.cn
Overview
EgoTouch is the first large-scale multi-view tactile dataset for egocentric hand-object interaction, featuring 208 diverse manipulation tasks across 1,891 episodes in both indoor and outdoor environments. The dataset provides synchronized multi-view video (egocentric + dual wrist cameras), bimanual 3D hand pose (42 joints), and dense continuous pressure maps from wearable tactile sensors. By combining global scene context with wrist-level observations of hand-object contact, TouchAnything enables comprehensive modeling of tactile feedback under realistic occlusion and viewpoint variation.

Abstract
Egocentric human video data, which captures rich human-environment interactions and can be collected at scale, has become a key driver of embodied intelligence research. However, existing egocentric datasets typically lack tactile sensing, a critical modality that provides direct cues about contact, force, and pressure in human-object interaction. Without such signals, models struggle to learn physically grounded representations of real-world interaction dynamics. While tactile sensors provide these cues, deploying high-quality tactile hardware at scale remains expensive and cumbersome. This raises a central question: can tactile feedback be inferred directly from visual observations, enabling scalable tactile supervision for egocentric video data and supporting physically grounded embodied learning? To enable research in this direction, we introduce EgoTouch, a large-scale multi-view egocentric dataset with dense tactile supervision for bimanual hand-object interaction. EgoTouch comprises 208 manipulation tasks spanning 1,891 episodes in diverse indoor and outdoor environments, with synchronized multi-view RGB (head-mounted egocentric and dual wrist-mounted cameras), bimanual 3D hand pose, and continuous pressure maps from wearable tactile sensors. Building on EgoTouch, we introduce TouchAnything, a baseline multi-view vision-to-touch prediction framework that uses the egocentric view as the primary input and flexibly leverages available wrist-mounted views at inference time. Experiments show that incorporating wrist-mounted views generally improves tactile prediction over egocentric-only input, achieving up to 5.0% relative improvement in Contact IoU and 6.1% relative improvement in Volumetric IoU. We will publicly release the dataset, code, and benchmark.
Key Features
First dataset combining multi-view synchronized video (egocentric + dual wrist cameras) with real tactile pressure data
Real continuous pressure distributions from wearable sensors, capturing fine-grained contact dynamics
Bimanual manipulation with 42-joint 3D hand pose annotations, enabling analysis of coordinated hand-object interaction
Precise frame-level synchronization across video, pose, and pressure, enabling accurate temporal modeling of contact events
Dataset Statistics
Dataset Comparison
EgoTouch is the first dataset to jointly provide multi-view video, bimanual hand pose, and real dense pressure data across diverse scenes.
| Dataset | In-the-wild | Hand Pose | Contact | Wrist Views | Hands | Objects | Frames |
|---|---|---|---|---|---|---|---|
| GRAB | MoCap | Analytical | Biman. | 51 | 1.6M | ||
| ContactDB | Thermal | Biman. | 50 | 375k | |||
| ARCTIC | MoCap | Analytical | Biman. | 11 | 2.1M | ||
| OakInk | MoCap | Analytical | Single | 100 | 230k | ||
| DexYCB | Est. | Single | 20 | 582k | |||
| ActionSense | Glove | Pressure | Biman. | 21 | 521k | ||
| HOI4D | Est. | Single | 800 | 2.4M | |||
| EgoPressure | Est. | Pressure | Single | 31 | 4.3M | ||
| EgoDex | Est. | Analytical | Biman. | 500 | 90M | ||
| OpenTouch | Glove | Pressure | Single | 800 | ~500k | ||
| EgoTouch (Ours) | Glove + Est. | Pressure | Biman. | 1000 | 2M |
Main Contributions
- We introduce EgoTouch, a large-scale multi-view egocentric dataset for bimanual hand-object interaction, comprising 208 tasks, 1,891 episodes, synchronized RGB videos from one head-mounted camera and two wrist-mounted cameras, bimanual 3D hand pose, and dense continuous pressure maps across diverse environments.
- We establish a multi-view vision-to-touch benchmark on EgoTouch, with evaluation protocols for seen and unseen objects and different camera-view configurations, enabling systematic analysis of how complementary wrist views affect tactile prediction.
- We propose TouchAnything, a baseline vision-to-touch model with cross-view fusion and view dropout training, supporting flexible inference with egocentric-only or multi-view inputs and improving tactile prediction when wrist views are available.
Data Collection Setup
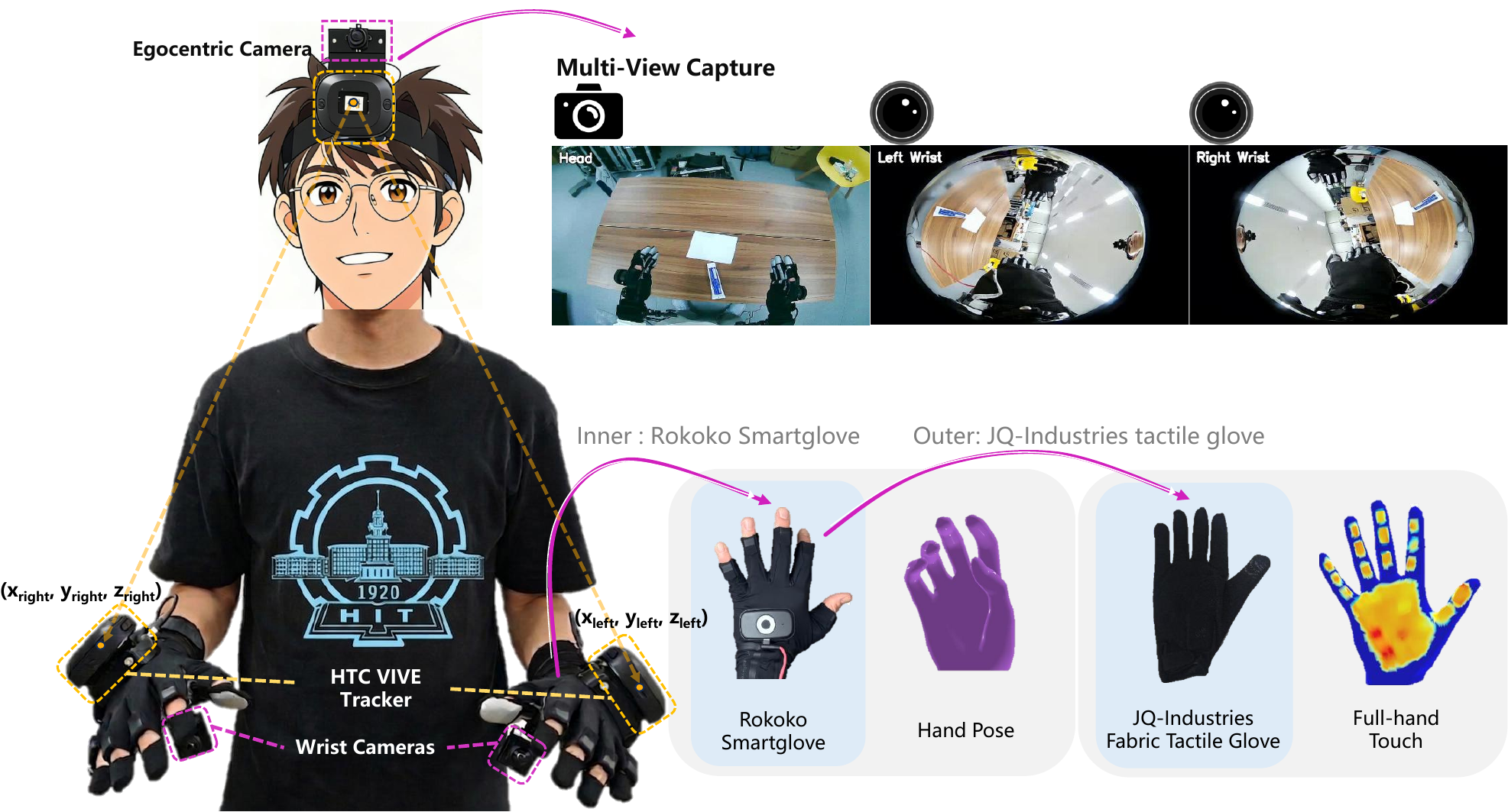
Multi-sensor data collection system with head-mounted egocentric camera, dual wrist cameras, and pressure-sensing gloves.
Our data collection system integrates:
- Head-mounted Wide-Angle Camera: Captures global manipulation context from a wide-field first-person perspective
- Dual Wrist Cameras: Observe hand-object contact regions to overcome occlusion
- Pressure-Sensing Gloves: Record dense 16×16 pressure maps on each palm
- Motion Capture: Tracks 42-joint bimanual 3D hand pose at 30Hz
- Temporal Synchronization: All modalities aligned with millisecond precision
Example Multi-Modal Data
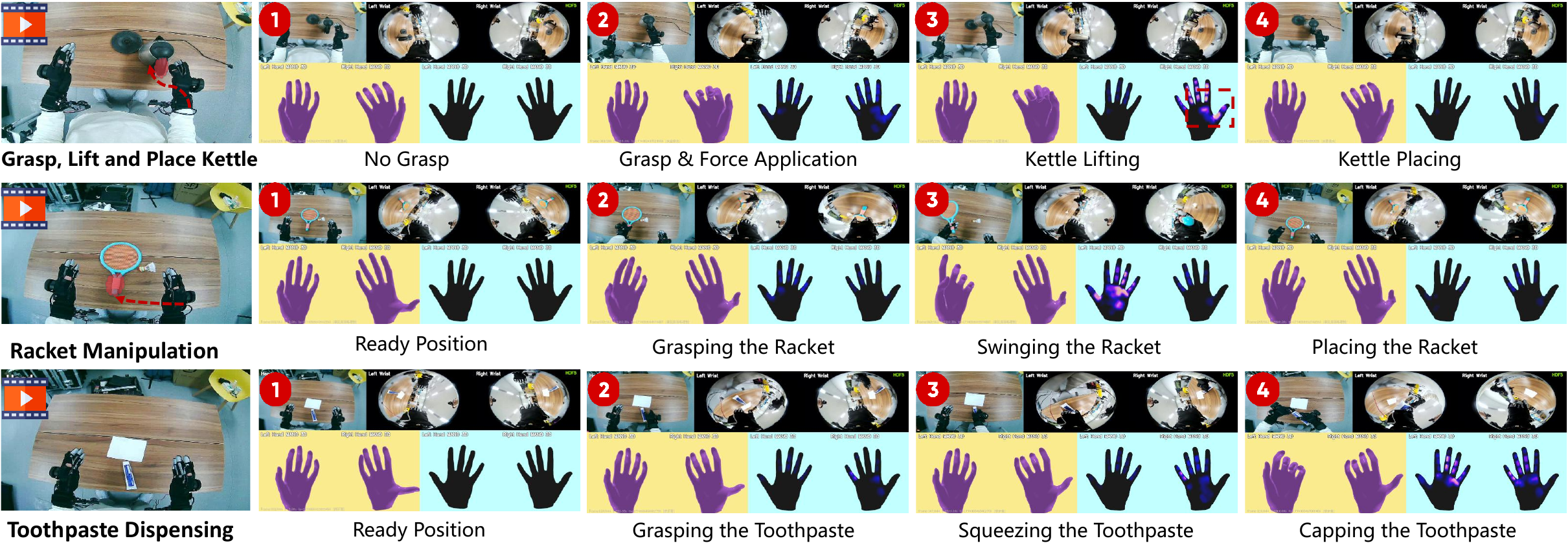
Example showing synchronized multi-view video, hand pose, and pressure maps revealing contact information invisible to vision alone.
Dataset Analysis
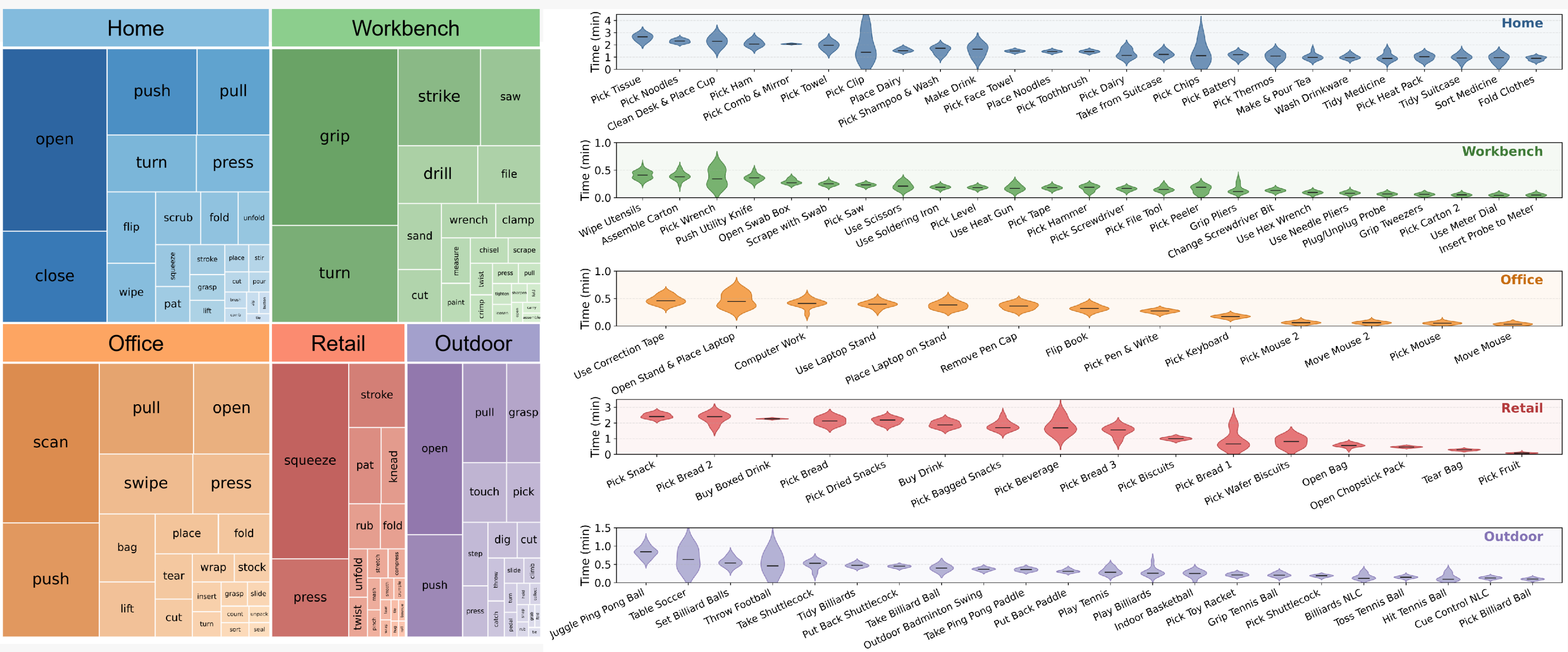
Comprehensive statistics showing diverse pressure patterns, balanced task coverage, and rich contact interactions.
Method Architecture
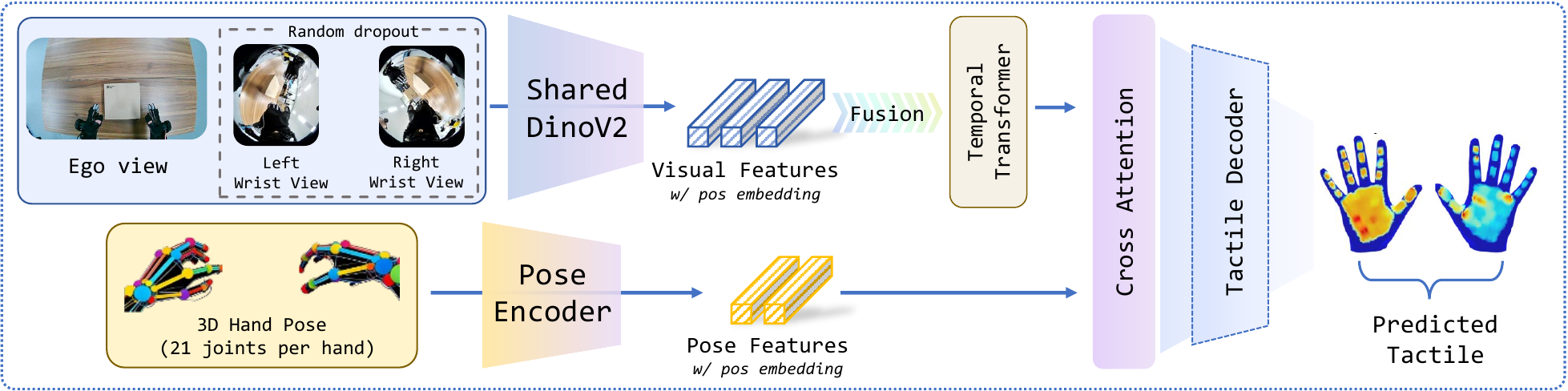
Multi-view tactile prediction architecture with shared vision encoding, cross-view attention, and pose-aware fusion.
We propose a multi-view tactile prediction model based on:
- Shared DINOv2 Vision Encoder: Extracts features from all camera views
- Learnable View Embeddings: Distinguishes between egocentric and wrist viewpoints
- Cross-View Transformer Attention: Fuses complementary information across views
- View Dropout Training: Enables robust inference with missing views
This design allows the model to work with any subset of available views at inference time, from ego-only to full multi-view, making it practical for real-world deployment.
Model Inference Results
Real-world tactile prediction results on diverse manipulation tasks. Our model accurately predicts contact regions and pressure distributions from multi-view video input.
Grasping Thermos
Multi-view tactile prediction during bimanual thermos manipulation
Handling Hair Dryer
Contact prediction on complex-shaped household appliances
Grasping Beverage
Accurate pressure estimation during bottle manipulation
Picking Up Mouse
Precise contact localization on small objects
Bouncing Ping-Pong Ball
Temporal contact prediction during dynamic interaction
USB Insertion
Fine manipulation with dynamic contact changes
These results demonstrate our model's ability to predict realistic tactile feedback across diverse manipulation scenarios, from static grasping to dynamic interactions.
Data Scaling Analysis
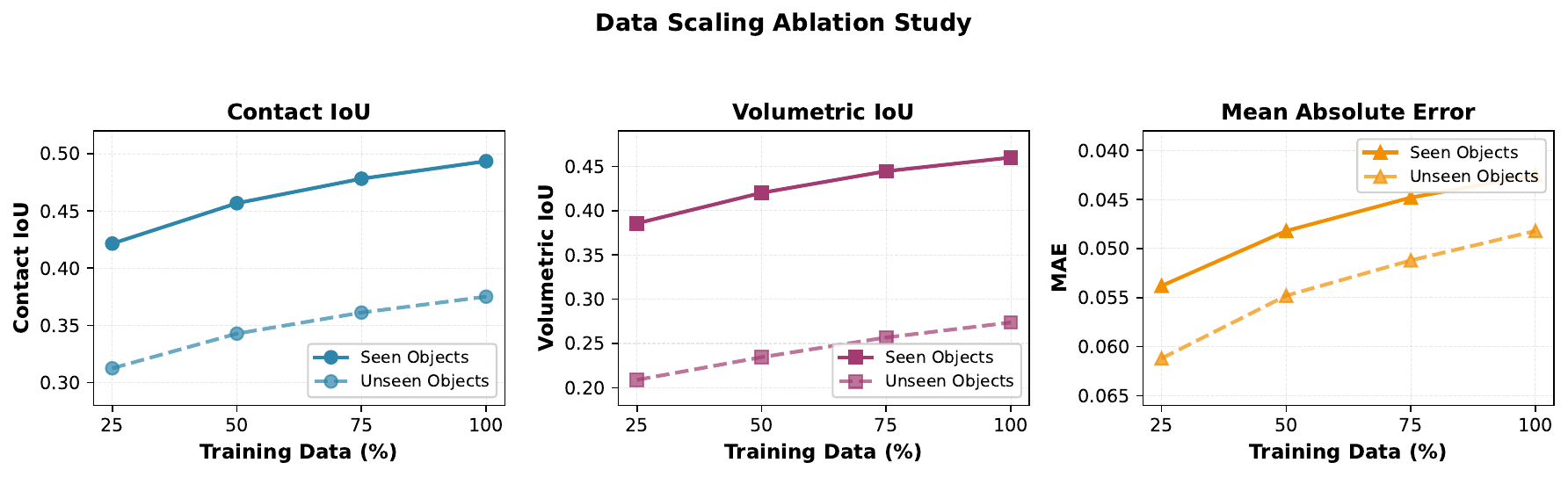
Performance improves consistently with more training data, demonstrating the model's ability to leverage large-scale datasets.
Qualitative Results

Tactile prediction results showing accurate contact region and pressure intensity prediction across diverse manipulation tasks.
Applications
Core Applications
See contact. Predict force. Enable reliable manipulation under occlusion.
Move beyond vision. Understand contact dynamics, grasp quality, and manipulation skills.
Broader Impact
Bring touch into virtual worlds through vision-driven haptic feedback.
Support vision-based sensory feedback for more intuitive prosthetic control.
Citation
If you find this project useful, please cite:
@misc{zhou2026touchanythingdatasetframeworkbimanual,
title={TouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video},
author={Jianyi Zhou and Ziteng Gao and Feiyang Hong and Zirui Liu and Guannan Zhang and Weisheng Dai and Ruichen Zhen and Chuqiao Lyu and Haotian Wu and Yinian Mao and Xushi Wang and Yuxiang Jiang and Wenbo Ding and Shuo Yang},
year={2026},
eprint={2605.13083},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2605.13083},
}Author Contributions
This work represents a collaborative effort across multiple domains, from hardware setup to model development and data collection.
Jianyi Zhou
- Paper writing and manuscript preparation
- Model architecture design and training
- Project website development
- Data collection participation
Ziteng Gao
- Data collection pipeline development
- Paper figure creation (partial)
- Experimental equipment management
- Data collection participation
Feiyang Hong
- Codebase organization and documentation
- Paper figure optimization
- Data collection participation
Zirui Liu
- Paper figure design and illustration
- Data collection participation
Guannan Zhang
- Project website video editing
- Data collection participation
Weisheng Dai
- Experimental equipment management
- Data collection participation
Ruichen Zhen
- Equipment procurement and acquisition
- Data collection hardware configuration
Chuqiao Lyu
- Data collection system setup and deployment
Haotian Wu
- Data collection hardware setup support
Yinian Mao
- High-level guidance and project support
Xushi Wang
- HaMeR inference framework development
- Data collection participation
Yuxiang Jiang
- Data collection participation
Wenbo Ding
- High-level idea discussions
Shuo Yang (Corresponding Author)
- Research ideation and project conceptualization
- Overall project supervision and research direction
- Model design and architecture consultation
- Technical guidance on system development and methodology
- Strategic planning of research scope and objectives
- Manuscript revision and high-level feedback